最大开源模型,再次刷爆纪录!Snowflake的Arctic,以128位专家和4800亿参数,成为迄今最大的开源模型。它的特点,是又大又稀疏,因此计算资源只用了不到Llama 3 8B的一半,就达到了相同的性能指标。
就在刚刚,拥有128位专家和4800亿参数的Arctic,成功登上了迄今最大开源MoE模型的宝座。
它基于全新的Dense-MoE架构设计,由一个10B的稠密Tranformer模型和128×3.66B的MoE MLP组成,并在3.5万亿个token上进行了训练。
不仅如此,作为一个比「开源」更「开源」的模型,团队甚至把训练数据的处理方法也全给公开了。
Arctic的的两个特点,一个是大,另一个就是非常稀疏。
好处就在于,这种架构让你可以用比别人少好几倍的训练开销,就能得到性能差不多的模型。
也就是说,与其他使用类似计算预算训练的开源模型相比,Arctic的性能更加优异。
比起Llama 3 8B和Llama 2 70B,Arctic所用的训练计算资源不到它们的一半,评估指标却取得了相当的分数!
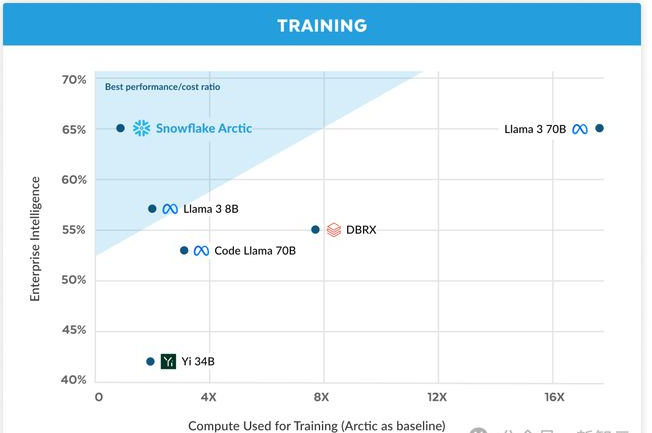
图1 编码(HumanEval+和MBPP+)、SQL生成(Spider) 和指令遵循(IFEval)的企业智能平均值与训练成本的比较从今天开始,Snowflake Arctic就可以从Hugging Face上获取了。
计算资源仅用一半,表现却和Llama 3 8B相当
团队发现,企业客户对AI有着一致的需求和使用场景——构建对话式SQL数据助手、代码助手和RAG聊天机器人。
为了便于评估,团队通过对编码(HumanEval+和MBPP+)、SQL生成(Spider)和指令跟随(IFEval)取平均值,将这些能力整合到「企业智能」这个单一指标中。
在开源LLM中,Arctic仅用不到200万美元(相当于不到3000个GPU周)的训练计算预算,就实现了顶级的企业智能。
更重要的是,即使与那些使用显著更高计算预算训练的模型相比,它在企业智能任务上也表现出色。
结果显示,Arctic在企业级评估指标上的表现,与Llama 3 8B和Llama 2 70B相当,甚至更优,而它所使用的训练计算资源却不到后两者的一半。
具体来说,Arctic使用的计算预算只有Llama3 70B的1/17,但在编程(HumanEval+和MBPP+)、SQL(Spider)和指令跟随(IFEval)等企业级任务上,都与其不相上下。