三种类型的专家混合模型 (Mixture of Experts, MoE) 简介
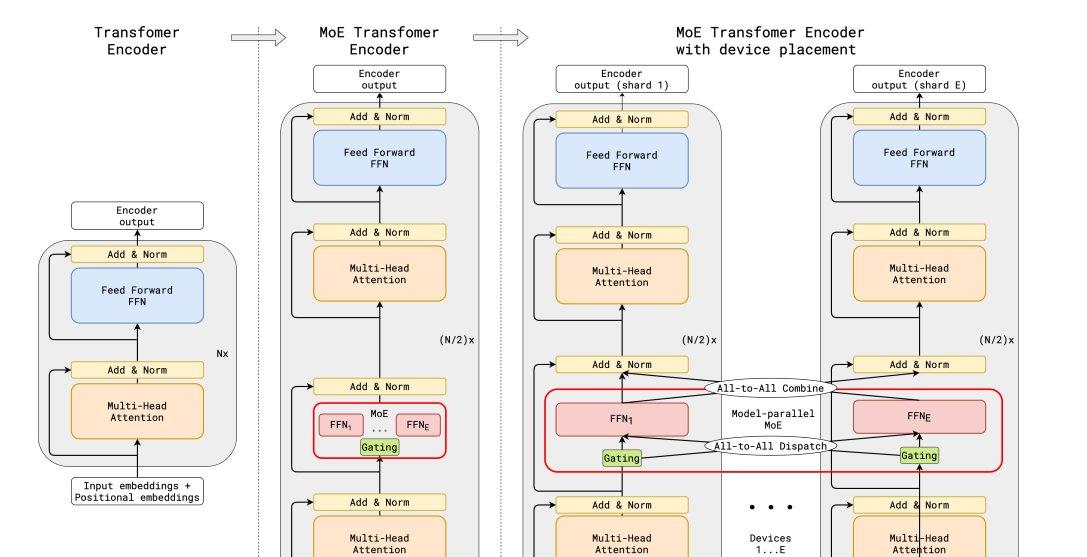
MoE 概述
MoE 使用稀疏的 MoE 层替换前馈层。这些层包含一定数量的专家(例如8个),每个专家都是一个神经网络(通常是前馈网络 FFN)。然后,一个路由器/门控网络负责挑选要使用哪些专家。MoE 具有以下特点:
- 预训练速度更快
- 根据激活参数的数量来看,推理速度更快
- 但如果你想让所有专家都加载到内存中,仍然需要大容量显存 VRAM
总的来说,就激活参数而言,MoE 往往优于具有相同参数数量的密集模型。
MoE 的例子包括:Switch Transformers、Mixtral、DBRX、Jamba DeepSeekMoE 等等。
预训练的 MoE
在固定的计算预算下,MoE 理论上可以比其密集对应物更快地达到相同的质量。这促使一些公司开始探索 MoE 预训练。
MoE 专家不是专门针对某个主题的。他们专门研究浅层概念或 Token 组。这是社区中一个常见的误解。
FrankenMoE
FrankenMoE 的灵感来自模型合并的大浪潮,并将其应用于 MoE。其思想是选择几个具有相同架构的微调模型,并从中构建一个 MoE。
它是如何工作的呢?假设你有一个性能非常好的代码微调模型和一个性能非常好的聊天微调模型。通过一些额外的训练(使路由器学会将每个 Token 发送到哪个专家),Token 被重新路由到相应的专家。
需要注意的是,这里我们有针对特定主题/任务的专家,这与预训练 MoE 的目标有很大不同。我对这种技术持保留态度,因为你失去了 MoE 的许多优势(不再有负载平衡)。
升级的细粒度 MoE
升级 MoE 的思想是选择一个已经训练过的基础模型(例如一个小型 Qwen 模型),并多次复制其前馈网络以创建多个专家。你甚至可以使用细粒度专家,这是 DeepSeek-MoE 引入的一个想法,意味着将前馈网络切割成更小的单元。这可以产生大量的小专家(甚至数百个专家),然后你可以控制要激活多少个专家。
初始化这个模型后,你就可以继续预训练,这应该需要更少的计算资源来实现高质量。
作者提供的更多内容,请查看原文链接。
@专家混合模型 @MoE @预训练MoE