大语言模型质量评估
✲ 大语言模型产品的评估系统
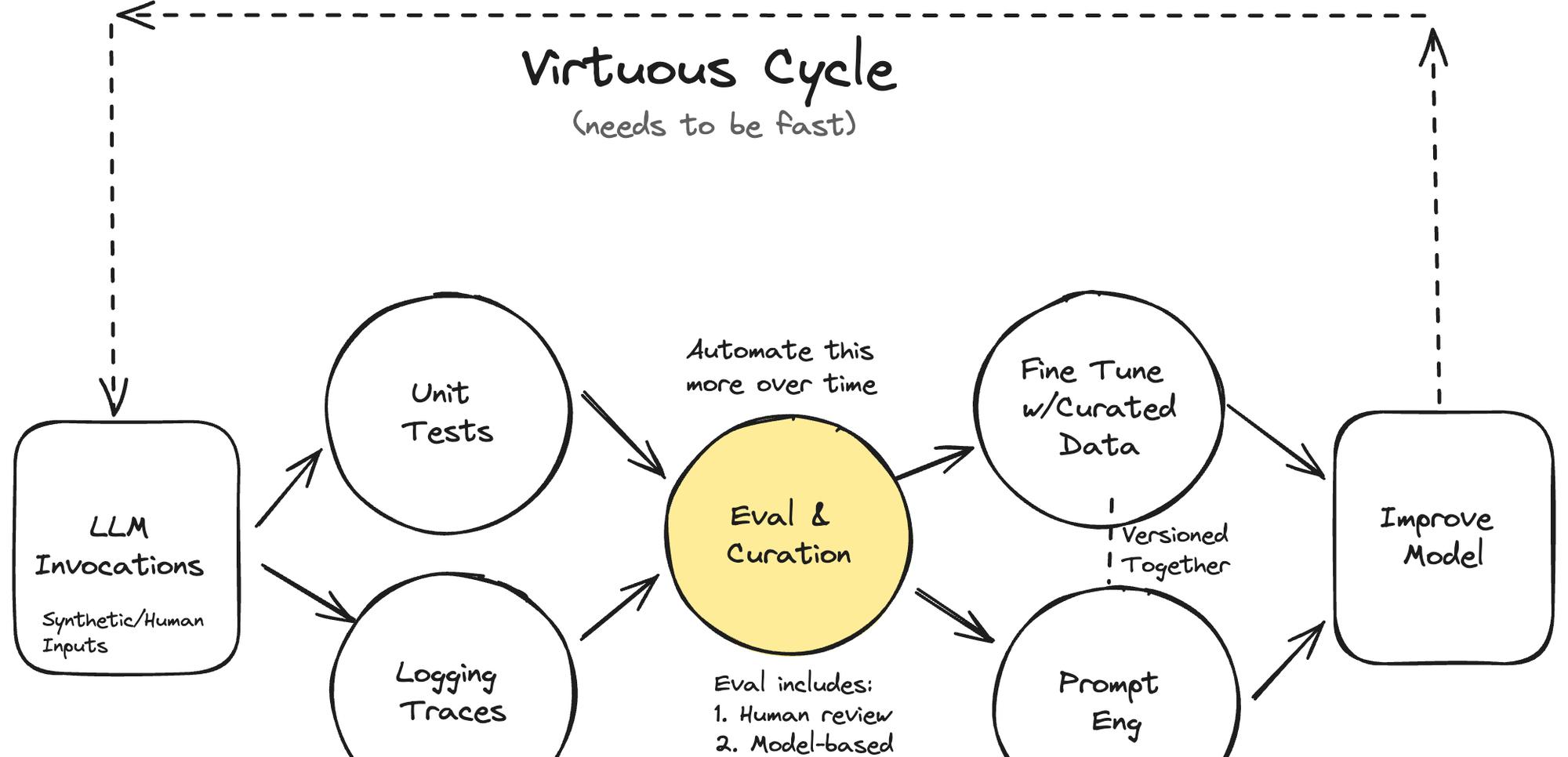
评估系统对大语言模型(LLM)产品的成功至关重要。许多 LLM 产品之所以失败,根本原因在于未能创建健壮的评估系统。评估、调试和改进是 LLM 产品成功的关键,而良好的评估系统可以创造一个良性循环,加速产品的迭代和改进。案例研究中的 Lucy 就是一个典型的例子,它初期通过提示工程取得了进展,但后来遇到了性能瓶颈,需要建立系统的评估方法来突破瓶颈。
✲ 评估的类型
LLM 产品的评估主要分为三个层次:单元测试、人工评估和模型评估、A/B 测试。单元测试是通过编写一些断言语句,在开发过程中快速获得反馈。人工评估和模型评估是通过人工检查和训练评估模型来评估整个系统。A/B 测试则用于确保 AI 产品能够驱动期望的用户行为或结果。除了评估整个系统,还需要对子组件如 RAG 进行单独评估。
✲ 单元测试的步骤
单元测试是 LLM 产品评估的基础,通常包括三个步骤:编写特定范围的测试、创建测试用例和定期执行测试并追踪结果。编写测试时要针对 LLM 的不同功能和场景,检验相应的断言。可以利用 LLM 自动生成测试用例,触发不同的场景。测试应当定期执行,利用 CI 基础设施可以很方便地实现自动化测试和结果跟踪。测试通过率并不一定要达到100%,而是要在错误容忍度和产品目标之间取得平衡。
✲ 人工评估和模型评估
人工评估和模型评估是更高层次的测试手段。首先要记录 LLM 系统的跟踪数据,包括用户的输入和系统的响应,为后续分析提供数据基础。在查看数据时,定制化的查看工具和良好的可视化非常重要。将人工评估结果与评估模型的预测对齐,可以极大提高评估的效率。随着评估模型性能的提升,可以渐进式地用自动评估来替代人工评估。
✲ 微调和数据合成与管理
评估系统所积累的数据和流程,可以很自然地应用到 LLM 产品的微调和数据管理中。微调最关键的是数据质量,而评估系统可以通过筛选、清洗、合成等手段来生成高质量的微调数据。评估系统中记录的跟踪数据、断言规则、人工反馈等,都可以直接用于微调数据的管理。总的来说,评估基础设施和微调及数据合成所需的基础设施有很大重叠。
✲ 调试
LLM 产品的调试也可以受益于评估系统。理想的评估系统应该能够支持快速定位错误,找到问题的根本原因。其中的关键是丰富的跟踪数据、可以标记错误的机制、高效的日志搜索和导航工具等。此外,系统的设计应当允许快速测试解决方案并验证有效性。总之,调试和评估所需的基础设施在很多方面是共通的。
全文翻译:点击阅读全文
@大语言模型 @质量评估 @评估系统