
文心千帆创建奖励模型训练任务
2023-07-19 16:36 更新
奖励模型训练是一种强化学习技术,用于根据人类反馈来学习如何更好地进行决策,从而获得更高的累积奖励值。在强化学习中,智能体通过不断地与环境进行交互,从中获得一定的奖励值。奖励模型可以描述和计算每一次交互中智能体获得的奖励值,并且根据这些奖励值,智能体可以学习到如何更好地进行决策,从而获得更高的累积奖励值。
奖励模型是强化学习中的一个重要概念,它直接影响智能体的学习效果和行为表现。
登录到文心千帆大模型操作台,在左侧功能列RLHF训练中选择奖励模型训练,进入奖励模型训练主任务界面。
创建任务
您需要在奖励模型训练任务界面,选择“创建训练任务”按钮。
填写好任务名称后,在范围内选择所属行业和应用场景,再进行500字内的业务描述即可。
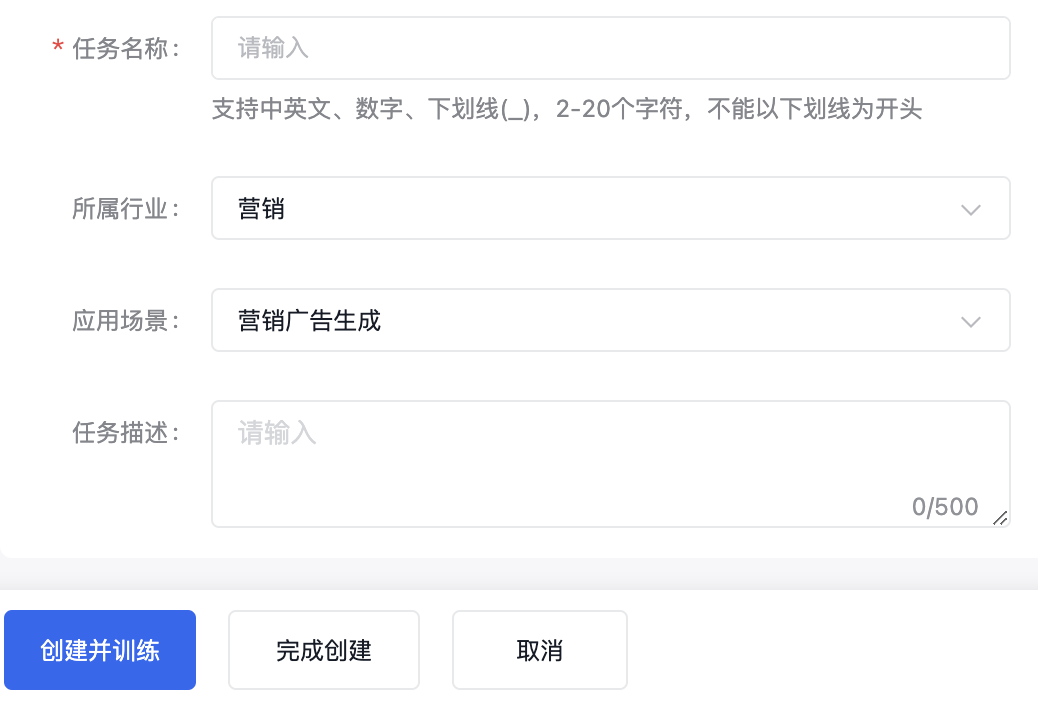
创建并训练直接开启训练模型的运行配置界面;“完成创建”仅创建任务不创建训练模型的运行。
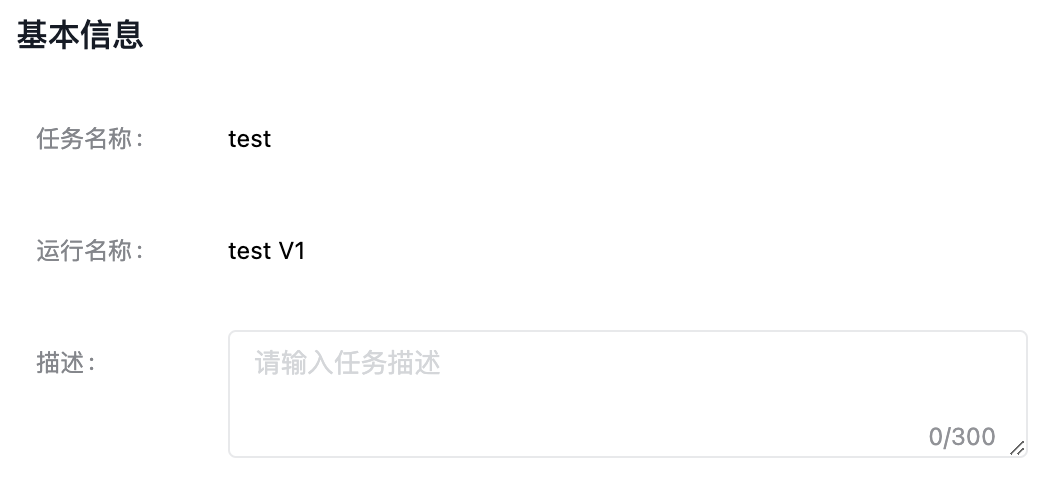
新建运行
您可以在创建任务时选择“创建并训练”,或者在奖励模型训练任务列表中,选择指定任务的“新建运行”按钮。进入模型训练的任务运行配置页,填写基本信息。
数据配置
训练任务的选择数据及相关配置,奖励模型训练任务匹配多轮对话-排序类的数据集。
建议数据集总条数在1000条以上,训练模型更加精准。
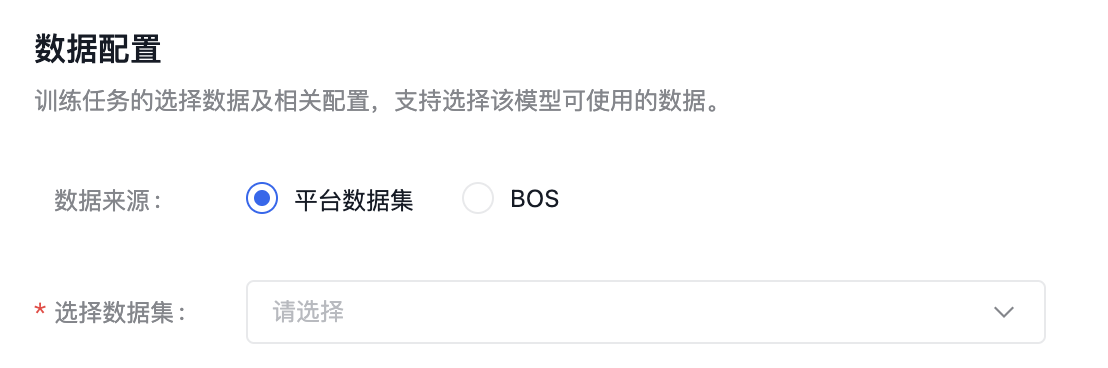
数据集来源可以为千帆平台已发布的数据集版本,也可以为已有数据集的BOS地址,详细操作内容可查看数据集部分内容。
需注意:当选择BOS目录导入数据集时,数据放在jsonl文件夹下。您需要选择jsonl的父目录:
- 奖励模型支持单轮对话、多轮对话有排序数据。
- RLHF训练支持仅prompt数据。
- SFT支持单轮对话,多轮对话需要有标注数据。
- BOS目录导入数据要严格遵守其格式要求,如不符合此格式要求,训练作业无法成功开启。详情参考BOS目录导入无标注信息格式和BOS目录导入有标注信息格式。
百度BOS服务开通申请。
以上所有操作完成后,点击“开始训练”,则发起模型训练的任务。